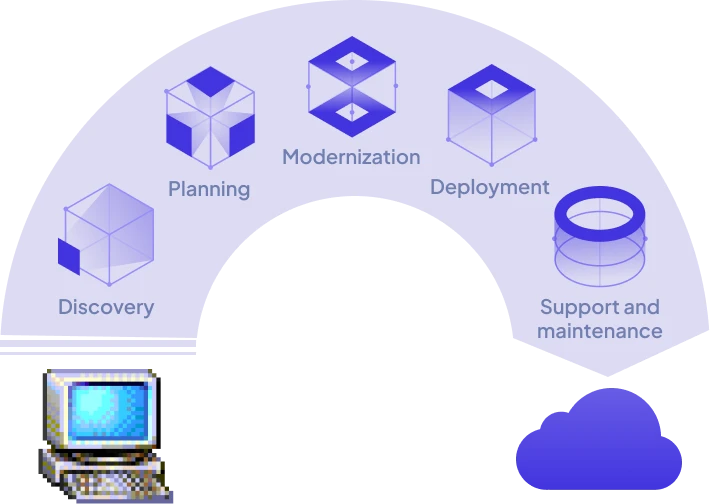
In the real world, it’s usually a mix.
The method we use is to write a plain English design document talking through your goals (for example, you may prefer managed services to not have to maintain as much software) and mapping those goals to technology choices.
As a general matter, we believe edges of systems (interface points) should be custom, so you can vary the technology behind the interfaces without as much pain. That is, when a given product goes end-of-life and you must replace it, an interface will save a lot of time and money.
Also, instrumentation is best left flexible, so having firebreaks throughout the system where you can emit custom logs and other performance information allows for much more robust monitoring, alerting, and overall a better experience from the business point of view (to say nothing of the improvement in DevOps quality of life, and thus cost).
We tend to make extensive use of third-party tech by default, but contained within a matrix that is under the full control of the client, to maximize ROI while minimizing several often-overlooked forms of risk:
- Dependency risk – will the open source module you rely on just break?
- EOL risk – when it goes end of life, how will you keep going without interruption?
- Security risk – will hackers insert code to that third-party open source repo and hack you?
- Cognitive-load risk – a dog’s dinner of many different technologies raises system complexity and ultimately time and money costs. Systems become hard to maintain, reason about, and change.